


客户介绍

DeepSeek 概述
DeepSeek已经发布了以下多个模型:
1. DeepSeek-V3参数量:6710亿参数,每个Token激活370亿参数。架构:采用混合专家模型(MoE)架构。性能:在多项基准测试中表现优异,尤其在数学和代码任务上表现突出。应用场景:通用大语言模型,适用于知识问答、内容生成、智能客服等领域。
2. DeepSeek-R1性能:在数学、代码生成和逻辑推理等复杂任务上表现出色。版本:包括DeepSeek-R1-Zero(完全基于强化学习训练的推理模型)。应用场景:推理任务,如数学竞赛、逻辑推理等。
3. DeepSeek-R1-Distill特点:通过知识蒸馏技术将DeepSeek-R1的能力传递到更小的模型中,降低推理成本。
方案案例
该公司业务分出品及制作两大板块,出品版块通过丰富的项目经验与资金支持,精准针对优质项目研发创作;制作版块通过主流的好莱坞电影制作工业化流程持续为客户提供包前期项目策划、后期特效制作的全流程服务广州名动

痛点
随着公司业务的不断拓展,知识管理方面的问题逐渐凸显。大量的技术文档、项目经验和行业洞察分散在各个部门和员工手中,缺乏统一的管理和共享机制,导致知识查找困难、重复劳动现象严重,大大降低了工作效率。同时,云存储模式下的数据安全问题也让公司深感担忧,公司需要严格遵守行业的数据安全法规和标准,确保敏感数据的安全性和合规性。此外,随着业务的日益复杂,公司对智能化办公和高效的知识管理需求也越来越迫切,希望能够借助人工智能技术,实现知识的智能检索、自动分类和精准推荐,提高员工获取知识的效率,促进创新和业务发展。
解决方案
为了解决这些问题,公司经过深入调研和评估,最终选择了私有化部署 AI 知识库和 DeepSeek 的解决方案。私有化部署 AI 知识库能够将公司的知识资源集中存储在内部服务器上,确保数据完全由公司自主掌控,从根本上解决数据安全和合规性问题。通过对知识资源的采集、整理和分析,构建一个结构化、智能化的知识库,实现知识的快速检索、智能推荐和协同编辑。而 DeepSeek 作为一款先进的人工智能模型,具有强大的自然语言处理和知识推理能力,将其集成到 AI 知识库中,能够实现语义搜索、智能问答等高级功能,帮助员工更准确地获取所需知识,提高工作效率。同时,定制化开发和系统集成确保了 AI 知识库和 DeepSeek 能够与公司的现有系统无缝对接,实现数据的共享和业务流程的优化。
解决方案全景图
用户本地制作文件,制作完成后提交渲云影视客户端渲染,在赞奇云工作站登录渲云影视客户端,将结果文件回传到云桌面并进行后期合成,支持多台机器同时打开文件并发加载图片进行合成;最后将合成的结果文件下载到本地,节省大量的时间。
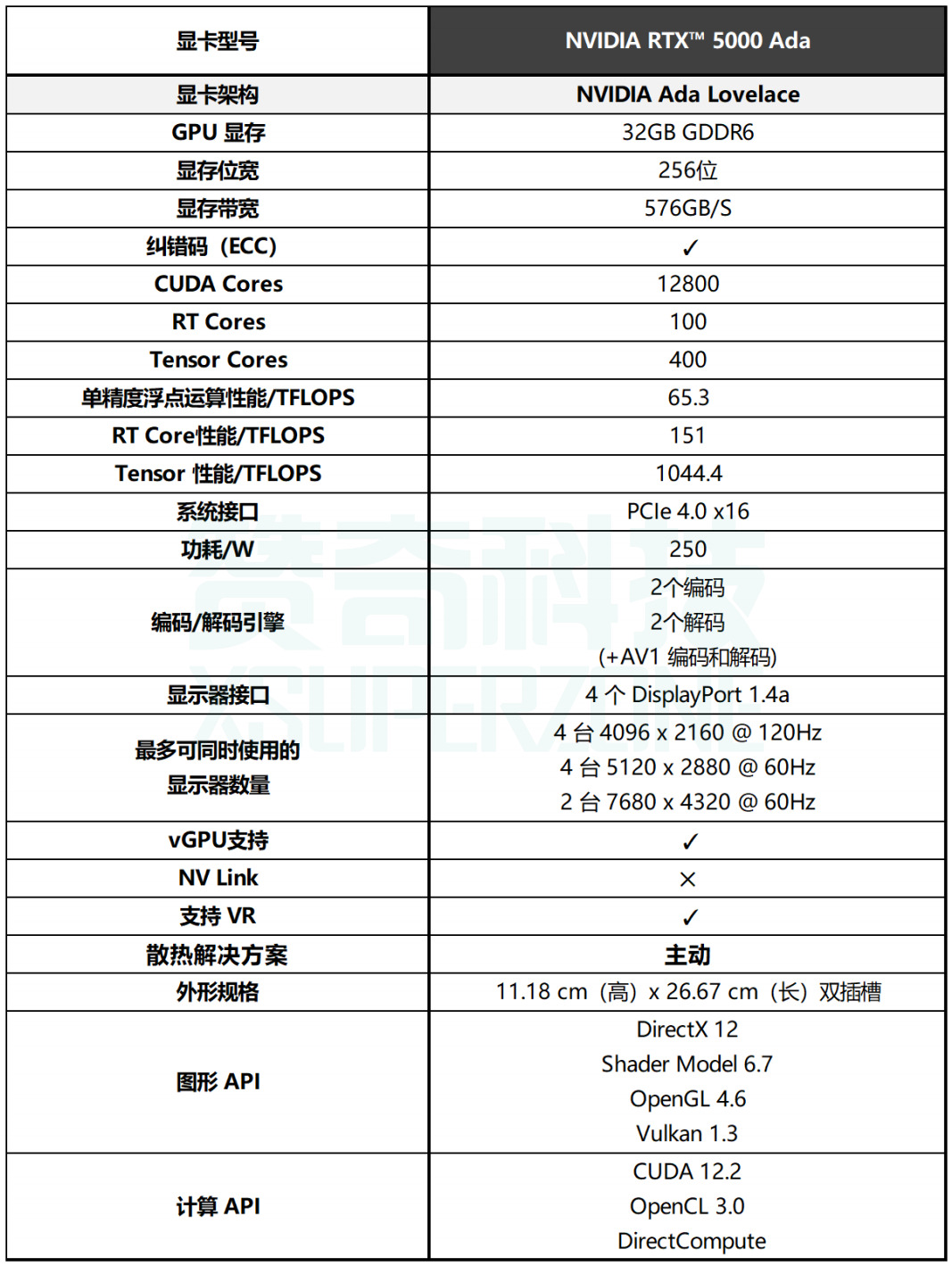
方案优势
一键轻松上云,助力高效办公
一、极致数据安全
私有化部署使公司掌控数据权限,按安全策略防护,杜绝数据泄露风险,保障数据安全合规。
二、高效工作助力
整合知识资源,实现快速检索与智能推荐,协同编辑避免重复劳动,显著提升工作与协作效率。
三、高度个性定制
依据公司业务和架构,定制知识库功能,无缝集成现有系统,提供个性化知识管理方案。
四、深度系统融合
与各类系统深度融合,实现数据互通、功能协同,为业务拓展和系统升级提供广阔空间。

